Lambda Tail Warming
An optimistic warming strategy to mitigate cold starts for low-traffic AWS Lambda functions.
If you're like me, AWS Lambda functions have become an integral part of your cloud toolbox. In fact, I use Lambda functions for just about everything. Whether I'm implementing change data capture with DynamoDB streams, executing complex state transitions in Step Functions, or rendering dynamic content for a web browser, Lambda functions are almost always the first compute solution I reach for.
Lambda functions have been a great choice for the vast majority of my use cases. They scale quickly to handle traffic spikes, and for asynchronous workloads, I never worry about cold starts. Even for synchronous workloads with minimal traffic, cold starts are mostly a non-issue. However, I have hundreds (maybe thousands) of synchronously invoked functions that receive infrequent and inconsistent traffic. Cold starts on those functions are not only painful to experience, but in some cases, can create upstream integration issues.
In this post, I'll outline a strategy I've been experimenting with that utilizes Lambda function lifecycle events to optimistically warm functions when there are no more active execution environments. I've been using this technique for a while now, and the results have been exceptional. Please note that this is not your standard trigger-with-a-scheduled-task Lambda Warmer that you've likely heard of in the past. This is a much more sophisticated approach designed to minimize costs, unnecessary invocations, and request collisions.
Traditional Lambda warming strategy
Many (many) years ago I created the fairly popular Lambda Warmer npm package. Its purpose was to optimize AWS Lambda function cold starts by implementing AWS best practices for warming functions "correctly". Those tips included:
- Don’t ping more often than every 5 minutes
- Invoke the function directly (e.g. don’t use API Gateway to invoke it)
- Pass in a test payload that can be identified as such
- Create handler logic that replies accordingly without running the whole function
A lot has changed in the last 6 years, but fundamentally, this technique still "works". The issue is that those warming pings happen every 5 minutes whether they're needed or not. This can lead to several unintended consequences.
- Unnecessary invocations: If Lambda functions are already "warmed" by actual traffic, sending regularly scheduled warming requests adds extra costs, resource usage, and CloudWatch log ingestion without providing any additional benefit.
- Blocked requests: Scheduled invocations will use a warm execution environment if one is available. It's possible that this can block actual traffic from using that warm environment and force a cold start on an end user's request. If you attempt to warm multiple Lambda execution environments, which requires intentionally delaying a response to force additional environments to spin up, you're highly likely to run into an end user blocking situation.
- Cold starts due to early termination: Lambda function execution environments (as of this writing) are typically recycled after approximately 6 minutes of inactivity. However, AWS may decide to recycle your environments early (or later) for any number of reasons, including internal failures. This happens a lot. If a user invokes your function before the next warming window, they are guaranteed to get a cold start.
Despite the issues above, this method remains quite popular as it's fairly easy to implement and inexpensive to run.
What about Provisioned Concurrency?
At AWS re:Invent 2019, AWS announced Provisioned Concurrency, a feature that allows you to "pre-initialize" Lambda execution environments. The promise of this feature seemed like a perfect solution. You simply specify how many "warm" Lambda functions you want (you can even manage it on a schedule or based on utilization), and AWS will make sure you have a warm, autoscaling fleet ready to go. As your function starts receiving traffic, the AWS Lambda service continues to warm new execution environments (without blocking) up to your pre-configured maximum. If you exceed your maximum, then it rolls over to standard on-demand scaling.
If you have a function that requires extremely low latency and is expected to get predictable periods of sustained traffic, Provisioned Concurrency is definitely worth looking at. However, the cost of this feature seems wildly expensive compared to other compute options. For example, the current Lambda Pricing charges $0.0000041667 for every GB-second of Provisioned Concurrency. For a function with 1024MB of configured memory, that would cost ~$0.02 per hour to handle ONE concurrent request. That doesn't include the PER invocation charge and the duration charges.
There are many benefits to using Lambda functions, most notably their wide array of Event Source Mappings (ESMs). ESMs make integrating with other AWS stream and queue-based event sources extremely simple and (mostly) headache free. But if you are using Provisioned Concurrency, it would almost certainly be for synchronous invocations like API requests, not for ESMs or other direct triggers like S3 and SNS. It depends on your use case and the amount of expected traffic, but in many cases, services like App Runner or ECS can provide auto-scaling containers that handle your traffic at a much more predictable cost.
For our use case, keeping at least one Lambda execution environment warm 24x7, would cost $10.80/mth (assuming 1024MB of configured memory). Also, that would be for EVERY FUNCTION we wanted to keep warm. Single-purpose Lambda functions have their uses, but at this price, you might want to think about building a MonoLambda (or Lambdalith).
Enter Lambda Tail Warming
Lambda Tail Warming is a technique that uses a Lambda Extension to track active execution environments by monitoring lifecycle events, then optimistically invoking itself to ensure at least one warm environment at all times.
The basic process is as follows:
- Install an external extension that subscribes to
INVOKEandSHUTDOWNevents from the execution environment. - When a new execution environment is started, you register the extension and persist the
extensionIdin an external datastore such as DynamoDB or ElastiCache. The record should also contain a time-to-live (TTL) value that expires after several minutes (more on this later). - If an
INVOKEevent is received after some amount of time has passed (more on this later), update the datastore record with a new TTL. - If the extension receives a
SHUTDOWNevent, check the datastore to see how many active execution environments are running. If there are one or zero, use the AWS SDK to asynchronously invoke the Lambda function usingInvocationType: 'Event'with a payload that indicates it's a warming event. - Remove the datastore record for current
extensionIdand exit the extension.
If you're unfamiliar with Lambda Extensions, AWS has a GitHub repository filled with several examples to guide you. External extensions can be written in a different language than the function, which means you can write this once and add it as a Lambda Layer to any function you want to warm. We'll look at a Node.js example, but you're free to adapt this to your preferred language. Let's build.
Building a Lambda Tail Warmer
This example from AWS shows the set up of a basic external extension. The extensions/nodejs-example-extension file is deployed to your Lambda function's /opts/extensions directory as part of the Lambda Layer or within a container (if using the container packaging format). This file is picked up by the Lambda runtime on initialization and will execute the index.js script in the nodejs-example-extension directory.
1#!/bin/bash2# Copyright Amazon.com, Inc. or its affiliates. All Rights Reserved.3# SPDX-License-Identifier: MIT-045set -euo pipefail67OWN_FILENAME="$(basename $0)"8LAMBDA_EXTENSION_NAME="$OWN_FILENAME" # (external) extension name has to match the filename910echo "${LAMBDA_EXTENSION_NAME} launching extension"11exec "/opt/${LAMBDA_EXTENSION_NAME}/index.js"
The example includes an extensions-api.js helper function that handles the interaction between the module and the Lambda runtime for us. We'll use its exported register and next methods in the main extension script.
Take a look at the sample extension script below. The main() function is executed immediately. It registers the extension using the register method, then enters a loop that awaits the next event from the Lambda runtime (await next(extensionId)). When a new event is sent from the runtime, the script parses the event type and then either executes the handleShutdown or handleInvoke methods. If it's a SHUTDOWN event, we also need to gracefully exit the extension using a process.exit(0).
1#!/usr/bin/env node2const { register, next } = require("./extensions-api");34const EventType = {5 INVOKE: "INVOKE",6 SHUTDOWN: "SHUTDOWN",7};89function handleShutdown(event) {10 console.log("shutdown", { event });11 process.exit(0);12}1314function handleInvoke(event) {15 console.log("invoke");16}1718(async function main() {19 process.on("SIGINT", () => handleShutdown("SIGINT"));20 process.on("SIGTERM", () => handleShutdown("SIGTERM"));2122 console.log("hello from extension");2324 console.log("register");25 const extensionId = await register();26 console.log("extensionId", extensionId);2728 // execute extensions logic2930 while (true) {31 console.log("next");32 const event = await next(extensionId);33 switch (event.eventType) {34 case EventType.SHUTDOWN:35 handleShutdown(event);36 break;37 case EventType.INVOKE:38 handleInvoke(event);39 break;40 default:41 throw new Error("unknown event: " + event.eventType);42 }43 }44})();
Now that we're familiar with how the extension handles lifecycle events, let's add our Lambda Tail Warming logic. Let's start by adding some variables to the top of our script:
1#!/usr/bin/env node2const { register, next } = require("./extensions-api");34// Require data layer5const data = require("./data.js");67// Require the AWS SDK Lamnda client8const { LambdaClient, InvokeCommand } = require("@aws-sdk/client-lambda");910const EventType = {11 INVOKE: "INVOKE",12 SHUTDOWN: "SHUTDOWN",13};1415// Init the extensionId16let extensionId: string;1718// Record the init time19let initTime = Date.now();2021// Refresh interval (for refreshing the Lambda instance record)22const refreshInterval = 10 * 60; // in seconds
Notice that I added a data import. This is referencing your own data module that would persist to the datastore of your choice. I provide some pseudo methods in the examples below to demonstrate the interactions. We also need the AWS SDK Lambda client. And I've moved the extensionId to the global scope (so we can access it later), created a variable to track when the extension was initialized (initTime) and set a refreshInterval for 10 minutes.
Next we create a new trackLambda function:
1// Persist execution environments ids2async function trackLambda(remove = false) {3 if (remove) {4 await data.remove(extensionId);5 } else {6 // Add a few seconds to the TTL to ensure the record is not removed before the next refresh7 await data.set(8 extensionId,9 {10 ts: Date.now(),11 },12 { ttl: refreshInterval + 10 }13 );14 }15}
If the remove argument is true, we remove the extensionId from the datastore, otherwise, we upsert the record with the current time and a TTL value slightly greater than our refreshInterval. The reason we do this is twofold. First, we want this record to expire if it doesn't get cleaned up by a SHUTDOWN event. I've yet to see an extension not get a SHUTDOWN event, but network failures and other issues are sure to leave some zombie records. This is a proactive approach to cleaning them up if something fails. We add a few seconds to the TTL to give a refresh request time to update the record before expiring.
Now we need our warmLambda function:
1// Warm the Lambda function2async function warmLambda(message) {3 const lambda = new LambdaClient({});45 const invokeParams = {6 FunctionName: process.env.AWS_LAMBDA_FUNCTION_NAME,7 InvocationType: "Event", // Async invocation8 LogType: "None",9 Payload: JSON.stringify({ warmer: true, message: `ID: ${message}` }),10 };1112 try {13 await lambda.send(new InvokeCommand(invokeParams));14 } catch (err) {15 // Log the error, but don't throw16 console.log(err, "warmLambda error");17 }18}
Here we initialize the Lambda client, then send an invocation to our function (process.env.AWS_LAMBDA_FUNCTION_NAME conveniently stores the name for us). We'll use an InvocationType of Event as we don't want to wait for a response. Lambda Extensions get between 500ms and 2000ms of processing time to perform any cleanup (500ms when registering a single extension), so we want this to be as efficient as possible. There is no guarantee that the Lambda service will respond in time, but it hasn't been an issue in all my tests. Also, if the invoke request fails, we want to catch the error and log it. This will only be called when the container is being shutdown anyway, but we want to make sure any other processes have a chance to run in the extension.
We need to update our handleShutdown function:
1// Make this async2async function handleShutdown(event) {3 // If the shutdown wasn't because of a failure4 if (event.shutdownReason !== "FAILURE") {5 // Get the list of active Lambda environments6 const environments = await data.list();78 // If there one or zero environments, sending a warming request9 if (environments.length <= 1) {10 console.log("WARMING THE LAMBDA");11 await warmLambda(extensionId);12 }1314 // Remove this Lambda instance record15 await trackLambda(true);16 }17 // Gracefully exit18 process.exit(0);19}
When our handleShutdown method is called, we first check to see if this was due to a Lambda Function failure. If it is, we likely don't want to keep trying to invoke a function that is failing. Otherwise, we retrieve a list of active environments from our datastore. If there are one or zero active environments (we assume that one is the current environment being shut down), then trigger the warming event. Regardless of the number of environments, we want to make sure we clean up the datastore record of the current environment by calling trackLambda with the remove argument set to true. Then we gracefully exit.
Our handleInvoke function also needs to be updated:
1// Make this async2async function handleInvoke(event) {3 if (initTime + refreshInterval * 1000 < Date.now()) {4 await trackLambda();5 initTime = Date.now();6 }7}
Most invocations we can ignore since we don't want to update the datastore on every request. But every so often we want to send a heartbeat to the datastore to let it know an execution environment is still active. Above I'm checking to see if we've exceeded the refreshInterval. If we have, we update the datastore by calling trackLambda() and reset the initTime.
Finally, we can update our main extension loop logic:
1(async function main() {2 process.on("SIGINT", () => {3 handleShutdown()4 .then(() => process.exit(0))5 .catch(() => process.exit(1));6 });7 process.on("SIGTERM", () => {8 handleShutdown()9 .then(() => process.exit(0))10 .catch(() => process.exit(1));11 });1213 const extensionId = await register();1415 // Add the Lambda environment to the datastore16 // Do not await (optimistic)17 trackLambda();1819 // Loop and wait for the next event20 while (true) {21 const event = await next(extensionId);22 switch (event.eventType) {23 case EventType.SHUTDOWN:24 await handleShutdown(event);25 break;26 case EventType.INVOKE:27 await handleInvoke(event);28 break;29 default:30 throw new Error("unknown event: " + event.eventType);31 }32 } // end while loop33})();
I've updated the SIGINT and SIGTERM event listeners to support the async handleShutdown function just in case we don't get our standard SHUTDOWN event. I've also added a trackLambda() call before we enter the loop (this is the INIT phase). I'm not awaiting this as we don't want it to block the extension's initialization. Then I added awaits to our handleShutdown and handleInvoke function calls. And that's it. Your Lambda Tail Warming is ready to go. Well, almost.
Configuring your Lambda function for Tail Warming
Before you can start warming your function, you have to make a few changes to ensure that the process will work correctly.
- Enable Invoke Permissions: In order for your extension to invoke your Lambda function, the function must have permission to invoke itself. You can add the following to your IAM role:
1- Effect: "Allow"2 Action:3 - "lambda:InvokeFunction"4 Resource: "{YOUR-LAMBDA-ARN}"
- Add a "warmer" event interceptor to your handler code: In order for your Lambda function to respond as quickly as possible and avoid potential request blocking, you'll need to modify your handler code to short circuit requests. This will ensure that any complex logic (and potential mutations and logging) is not processed. For example:
1// Handler2exports.handler = async function (event, context) {3 if (event.warmer) {4 return { warmed: true };5 } else {6 // Run my normal function code7 }8};
- Enable datasource access permission: In addition to the necessary Lambda Invoke permissions, you also need to make sure that the Lambda function has access to the datastore you're using to persist execution environment information.
How does this perform?
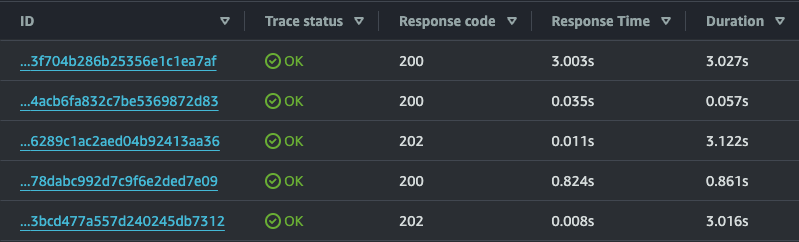
Below are the traces for a rather large Lambdalith that includes the canvas binary to generate and manipulate image files. The first trace is the typical cold start (~3 seconds) for this application. The second 200 request below is a typical warm invocation (< 60 milliseconds). The subsequent request is a Tail Warming event (note the 202 status code as this is happening asynchronously). This is a cold start (remember we do this immediately after the SHUTDOWN event of the last environment) which initializes a new execution environment and has a total duration of 3.122 seconds.
The next invocation shows a request from a user with a response time of 824ms. This application loads a significant amount of state, which typically happens during a normal user request. Our warming event short circuits this, which is why we see some additional response time during this invocation. It is possible to load state or perform some other actions during our warming event, but the goal is to find the right balance between cost and performance. The warming event saves us over 2.2 seconds of initialization time on the first subsequent user request and costs us only about 10 ms of billable time.
Other things to consider
There are several ways to improve this technique and make it more intelligent:
- The
refreshIntervalcould be tweaked to support shorter expirations or more frequent datastore heartbeats. I found 10 minutes makes the most sense as it prevents premature removal of datastore records when the app is handling real traffic from users. - It's possible that a failure (network issue, missed
SHUTDOWNevent, etc.) could prevent the warming event from triggering. This would break the cycle of warming events, meaning the next real invocation would get a cold start. You could mitigate this by periodically checking the datastore for active records or by attaching listeners (like using DynamoDB Streams) that would do something similar. This would be in a separate process (e.g. Lambda function), so it wouldn't block invocations to the primary function unless you needed to warm it. It would add to the cost, but if you were warming multiple functions, this would benefit from the economies of scale. - You can add controls to turn this on and off. Extensions have access to Lambda environment variables, which are a handy and low latency way to add state to every invocation without needing to redeploy or fetch external configurations. A function configuration update could be scheduled if you wanted to automate this.
- You could hydrate the state on every warming event. As I mentioned before, the majority of cold start time is typically during the initialization stage. If it makes sense to load some of that state on a warming event, then feel free to.
- You could combine this strategy with the traditional Lambda Warming technique. When you invoke a "warm" function, this will generally extend the duration of that execution environment. That includes maintaining any global state that has been loaded. As long as an execution environment stays warm, the Tail Warming will never fire. When the environment is eventually recycled, the Tail Warming would immediately invoke a new one.
- You could potentially use the extension to send pings to warm environments before a
SHUTDOWNevent. External extensions run as a separate process and might be able to use a combination ofINVOKEevents and internal timers to proactively warm functions that haven't received any recent activity.
Why would you use this?
You're probably thinking to yourself, "This seems quite complicated, why not just use the traditional Lambda warmer or optimize my functions to reduce cold starts?" If done manually, then yes, I agree that the implementation is overly complex and may not be worth it. However, if you automate this as part of a larger project, I believe it provides a smarter, less intrusive, and more cost effective approach.
In many of my use cases, I have Lambda functions that sit idle for several hours, then suddenly receive a burst of traffic. This often happens with low traffic administrative dashboards or webhooks for upstream services like Slackbots. That first cold start can be an awful experience, and if the system is outward facing, can sometimes be enough for the user to abandon the page altogether. For Slackbots, the initial response must be within a strict 3 seconds. Without warming, the application we traced earlier would almost certainly fail to meet that requirement.
Optimizing your functions is a path worth exploring, but there is also the question of effort versus reward. If I shave 200ms off a 3,000ms cold start, that's great, but it likely won't come close to having as much of an impact as using a warming strategy. If you do employ a warming strategy, I think it should be slightly smarter than just sending a scheduled warming ping.
When should you use this?
This works best when you have low traffic functions with prolonged periods of inactivity between invocations. Even if you have periods where there are no requests for 5-10 minutes, cold starts will almost certainly creep in. And since this solution maintains state, you don't have to worry about warming pings colliding with actual user requests during times with consistent traffic. If you have several warm execution environments, SHUTDOWN events simply won't send a ping.
Wrapping Up
This technique is experimental and definitely has room for improvement. As I collect more data, I hope to expand upon its capabilities and perhaps codify some more complete examples. If you have any thoughts or feedback, please be sure to reach out on X or LinkedIn.
We've implemented a beta version of this on Ampt that can be enabled with a single checkbox. If you'd like to try it out, you can sign up for free.